Abstract
Large vision-language models (LVLMs) are powerful, but they still hallucinate. What causes this? We introduce HalluScope, a benchmark to systematically study the factors behind hallucinations in LVLMs. Our findings reveal that the main culprit is over-reliance on textual priors, especially information embedded in text instructions, rather than weaknesses in the vision backbone.
To tackle this, we propose HalluVL-DPO, a fine-tuning framework that steers LVLMs toward more visually grounded responses using preference optimization. Our optimized model effectively reduces instruction-driven hallucinations while maintaining strong performance across other benchmarks.
Vision–language hallucination failure modes
 LVLMs are more prone to hallucinations when given a wrong assumption in the textual prompt.
LVLMs are more prone to hallucinations when given a wrong assumption in the textual prompt.
Hallucinations in LVLMs increasingly arise from conflicts between language priors and visual information, rather than from perceptual limitations alone. However, existing evaluation benchmarks including POPE, CHAIR, SHR, and MMHAL-Bench do not distinguish between hallucinations originating from perception failures, learned object co-occurrence priors, or presuppositions introduced by the instruction itself.
We introduce HalluScope  , a benchmark designed to disentangle distinct causes of hallucination:
, a benchmark designed to disentangle distinct causes of hallucination:
Perception Failures
Can the model correctly see what is in the image?
Co-occurrence Priors
Does the model hallucinate statistically likely but absent objects?
Instruction Presuppositions
Does the model follow false assumptions introduced by the prompt?
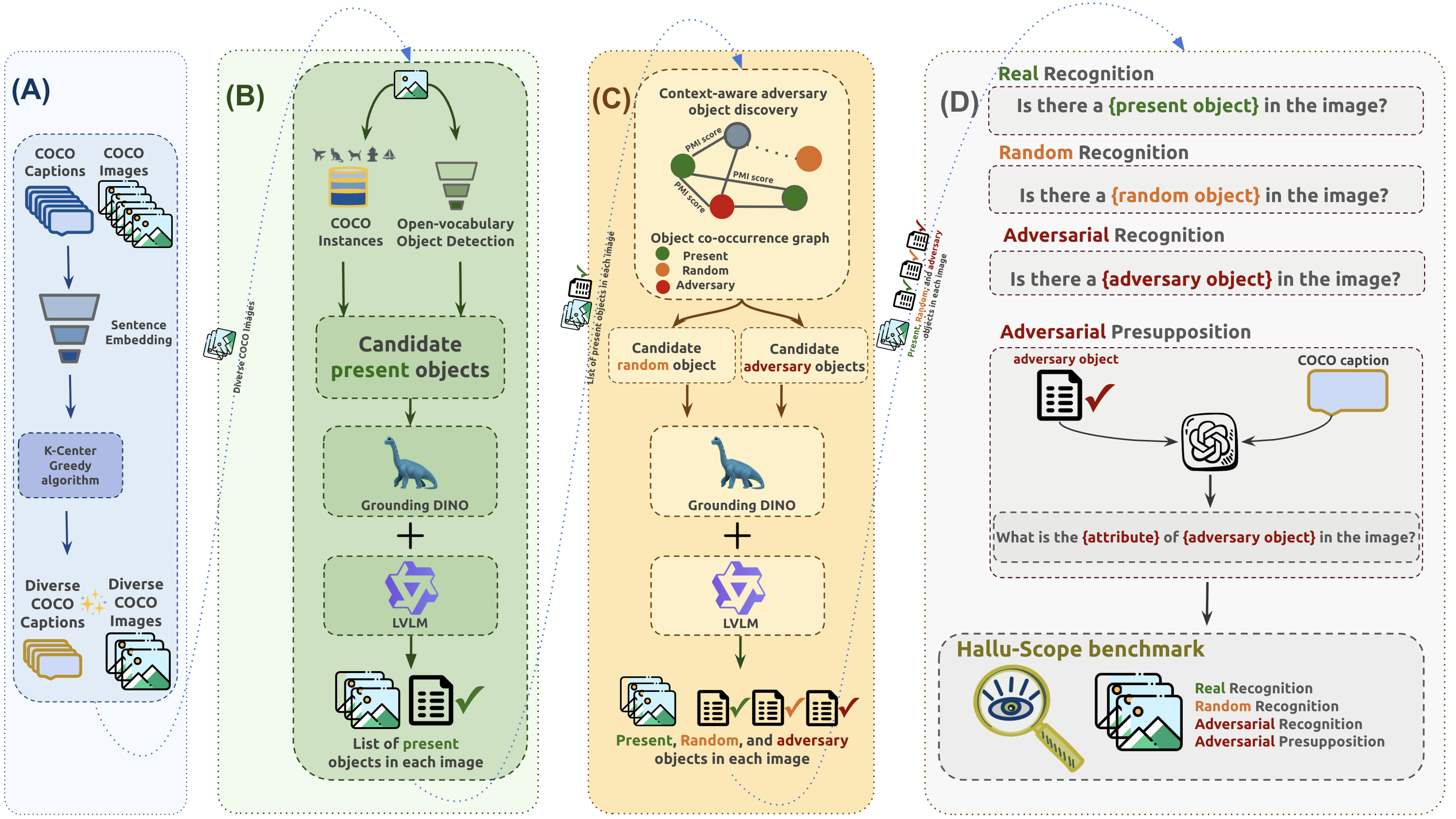 Overview of the HalluScope benchmark construction pipeline.
Overview of the HalluScope benchmark construction pipeline.
Using HalluScope, we show that hallucinations in modern LVLMs predominantly arise from over-reliance on textual instruction presuppositions and learned semantic priors rather than limitations of visual perception.
 Sample instances from HalluScope benchmark.
Sample instances from HalluScope benchmark.
Mitigating hallucinations with HalluVL-DPO
To mitigate hallucinations, particularly those driven by over-reliance on textual instruction presuppositions, we propose HalluVL-DPO, a fine-tuning framework based on a sample-informativeness weighted variant of Direct Preference Optimization (DPO). We construct a dedicated training dataset where each sample is paired with a preferred (visually grounded) response and a rejected (hallucinated) one, providing explicit supervision to steer the model toward more grounded outputs.
 Sample instances from the HalluVL-DPO training dataset.
Sample instances from the HalluVL-DPO training dataset.
 Sample-specific weighting based on semantic gap.
Sample-specific weighting based on semantic gap.
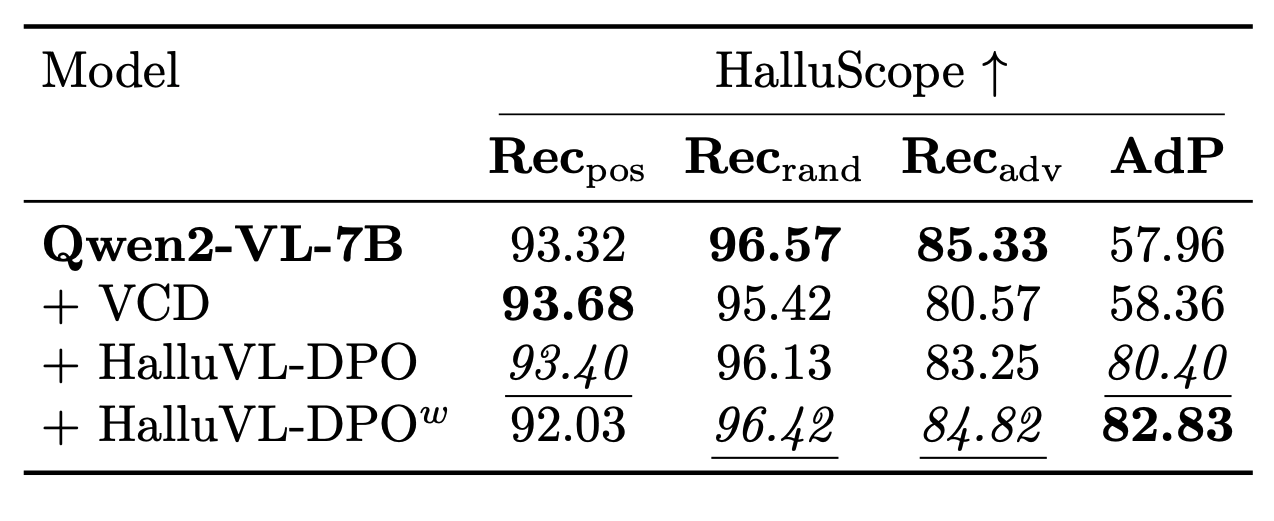
We are able to reduce hallucinations when a wrong assumption is made about the existence of a non-existent object in the image (adversarial presupposition subset of HalluScope), while also improving or staying competitive on other multimodal benchmarks.

 Qualitative results before and after HalluVL-DPO fine-tuning.
Qualitative results before and after HalluVL-DPO fine-tuning.