
Projects
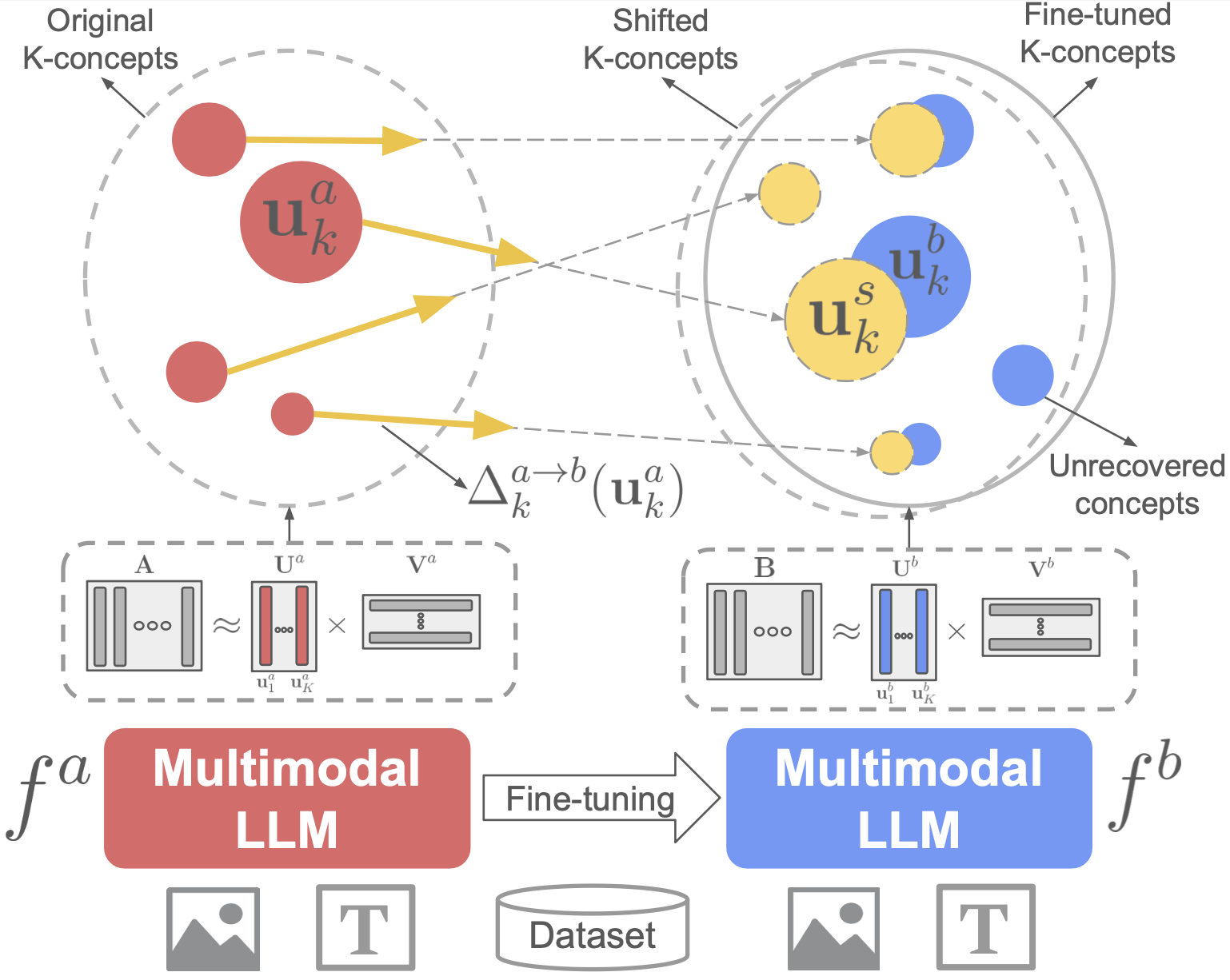
Analyzing Fine-tuning Representation Shift for Multimodal LLMs Steering alignment
We systematically analyze the evolution of hidden state representations to reveal how fine-tuning alters the internal structure of a model to specialize in new multimodal tasks. Using concept-based shift vectors, we can recover fine-tuned concepts and steer model behaviors without any training.
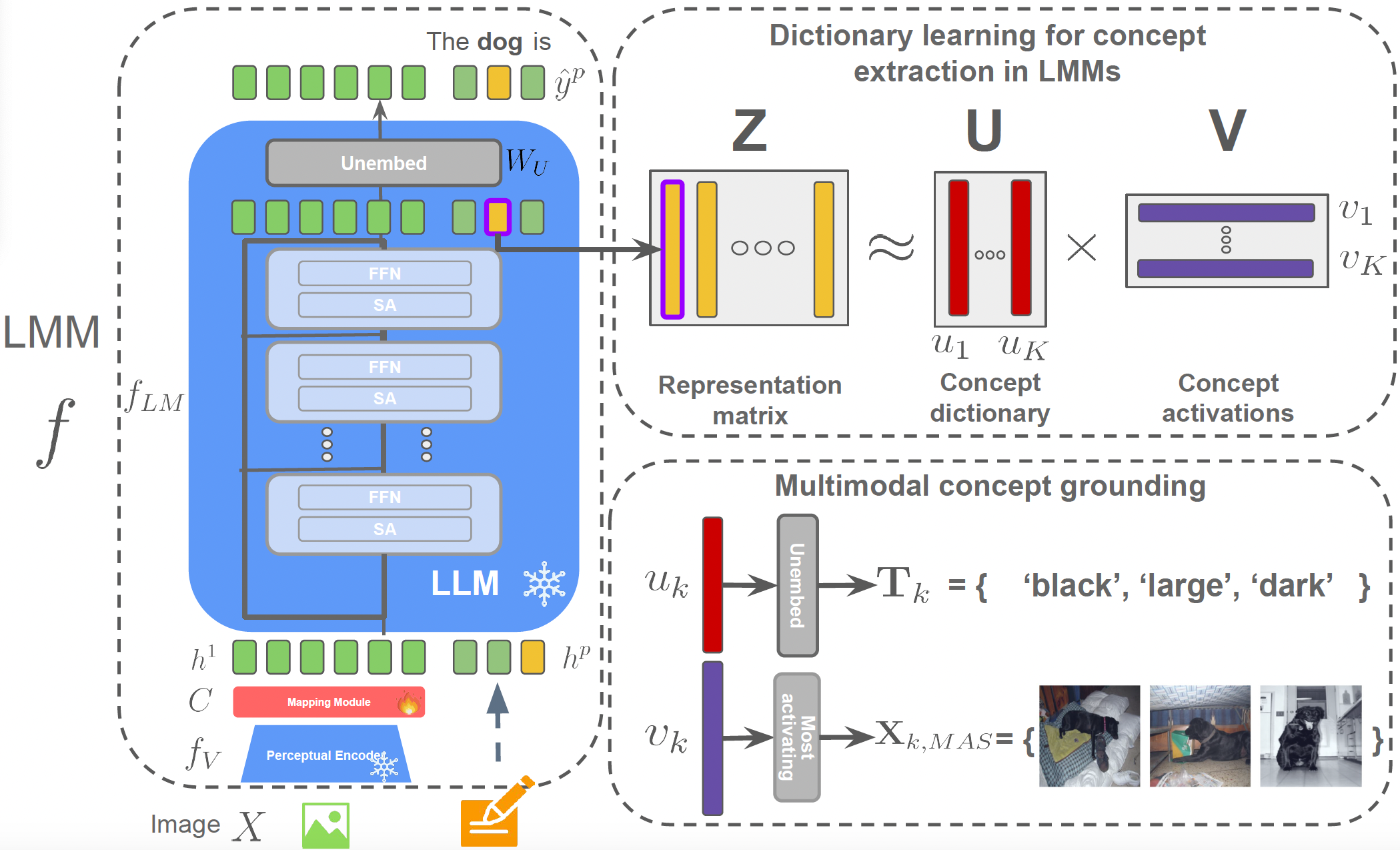
A Concept-Based Explainability Framework for Large Multimodal Models
A novel framework for interpreting large multimodal models using dictionary learning applied to token representations. The learned dictionary elements correspond to well-grounded multimodal concepts, evaluated for disentanglement and visual-textual grounding quality.
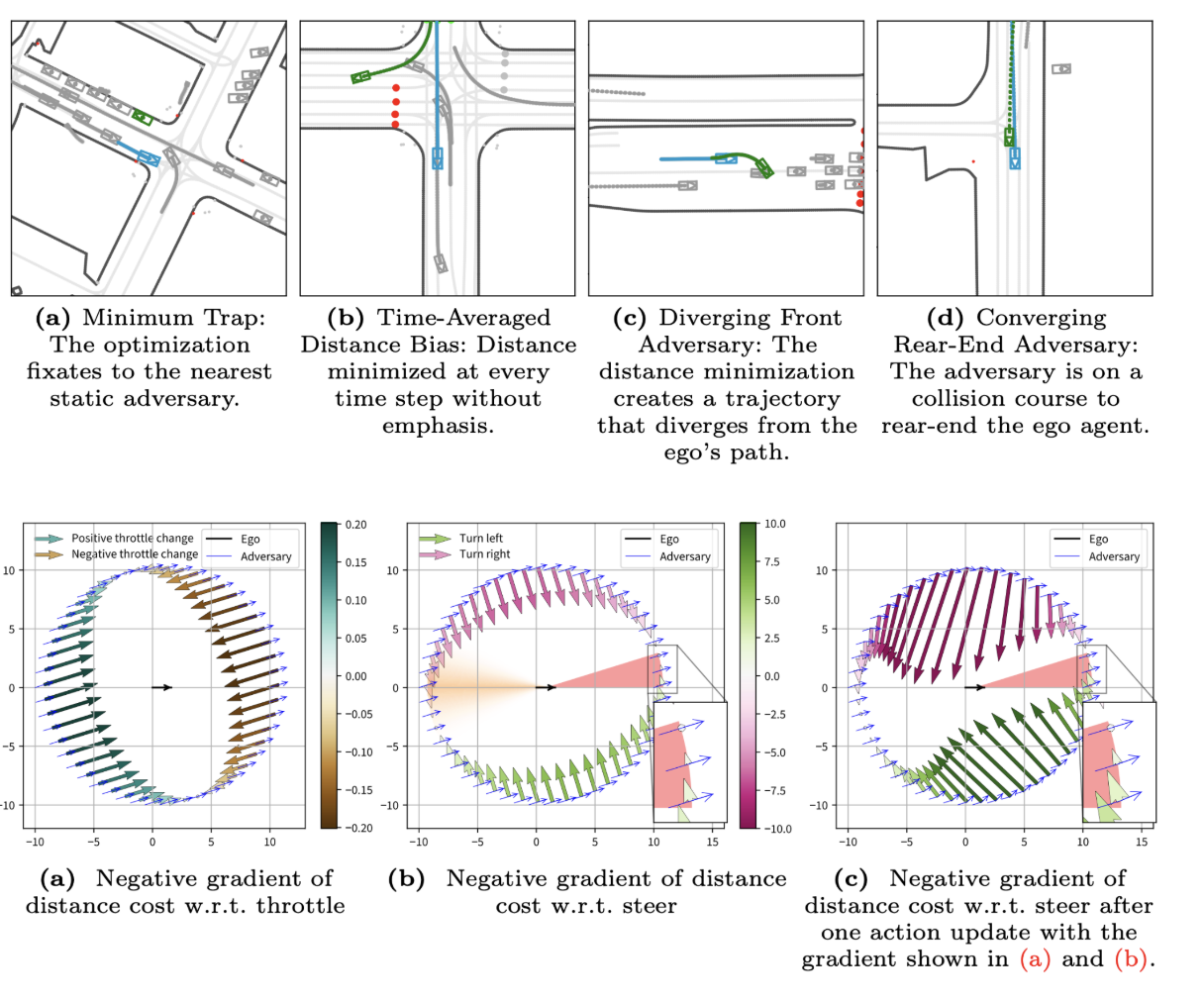
ReGentS: Real-World Safety-Critical Driving Scenario Generation Made Stable
A framework for generating safety-critical driving scenarios by modifying real-world regular scenarios through trajectory optimization. ReGentS stabilizes generated trajectories and introduces heuristics to avoid unrealistic diverging paths and unavoidable collisions, scaling to up to 32 agents via a differentiable simulator.
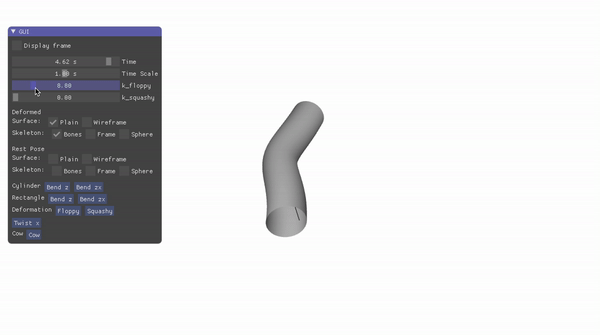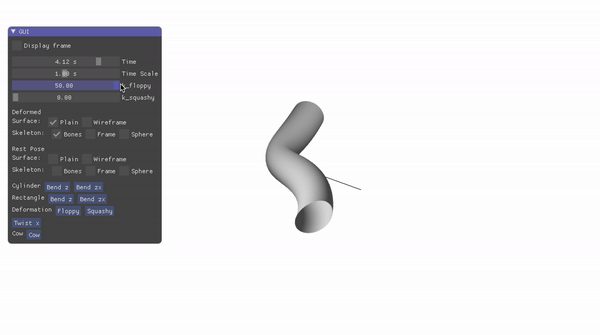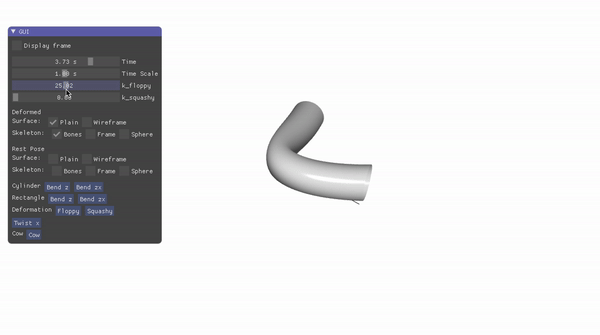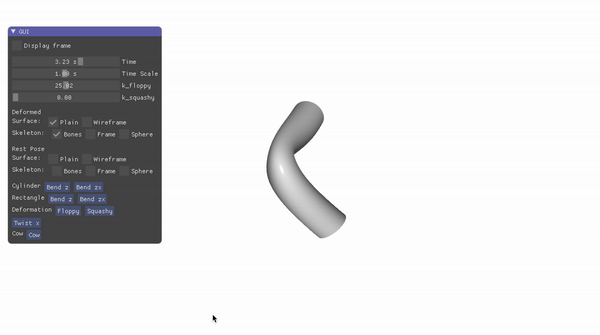

Landmark Localization for a Fashion Dataset: A PIFPAF Plugin
An OpenPifPaf plugin for detecting key landmarks — such as sleeve ends in shirts — across various clothing items in a fashion dataset.